How I Tested the Cross‑Lingual Hints Hypothesis for Expat Mode
Unlock the secrets of efficient language learning! Discover how a cross-lingual hints system can speed up your Spanish skills while living in Spain. Learn the surprising findings from real textbook analysis and how AI tools streamline the process

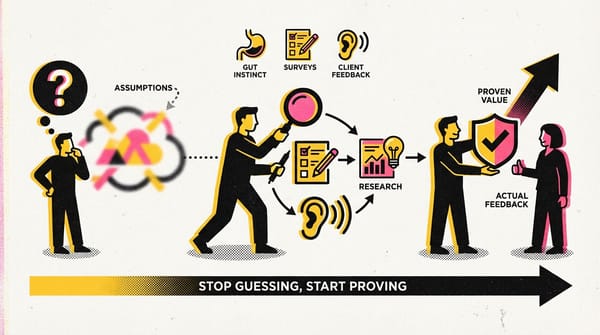
In my previous post I wrote about expat mode: a scenario where a Russian‑speaking learner lives in Spain, already knows English, and is now pushing Spanish to a functional level. After shipping the basic version of the bot, the next task was to validate one specific feature:
Can an EN↔ES cross‑lingual hints system actually speed up learning, instead of just decorating the interface?
The Problem I Started With
From my offline experience: when I was learning Spanish, my teacher constantly tied it back to English:
- “Here it’s almost like Present Perfect.”
- “This construction behaves like in English, with this exception.”
This took a lot of load off my brain: I did not have to learn everything “from scratch”, I could lean on structures I already knew.
When I translated this into product work, the hypothesis looked like this:
- Textbooks should contain many natural contact points between EN and ES.
- If I collect and package those into hints, it should be easier for an expat to transfer knowledge from one language to the other.
- So in the bot I just need a “Compare with EN/ES” button and a way to pull a relevant mapping.

Reality: Far Fewer Mappings Than It Seems
I took 4 textbooks, about 200 units, and started looking for real overlaps:
- similar tenses
- similar structures
- typical traps for Russian speakers
Once you formalise all of this, the rose‑tinted glasses come off quickly:
- just 68 pairs between units
- and 37 EN↔ES grammar mappings
From a teacher’s perspective, “there are a lot of similarities”.
From a product perspective, there are not that many, if you care about UX and hint quality.
Some of those “similarities” turned out to be:
- either too superficial
- or actively confusing (false friends, different usage ranges, etc.)
How I Collected the Data: Perplexity + Claude as a Product Stack
Doing all of this manually would have taken weeks. So I immediately went to an AI‑tool stack and built a small pipeline.
1. Perplexity — Research and Academic Backbone
I asked Perplexity for EN↔ES grammar mappings under a very specific context:
I'm building a bilingual learning app for RUSSIAN speakers
learning ENGLISH and SPANISH simultaneously (expat in Spain scenario).
Need: Grammar concept mappings between EN↔ES that help learners
transfer knowledge. Focus on:
- Tense correspondences (where they align and differ)
- Structural similarities (word order, articles, etc.)
- Common mistakes Russians make in both languages
- False friends to warn about
Output: JSON format for direct importThe result was 37 grammar mappings in JSON, ready to import. That removed hours of routine work: searching, structuring, and normalising data.
Here Perplexity works as an “academic co‑author”: it pulls in research, keeps the language precise, and avoids “pop linguistics”.
2. Claude Sonnet — Semantic Matcher for Units
The next layer is not abstract grammar but specific textbook units.
I give Sonnet lists of English and Spanish units and ask it to find pairs:
Analyze these English and Spanish textbook units.
Find units that teach the SAME or SIMILAR grammar concepts.
English units: [list]
Spanish units: [list]
For each match, provide:
- en_unit, es_unit
- concept_en, concept_es
- relationship (why they match)
- mapping_type: exact/similar/partial
Output: JSON array, 25-35 mappingsHere it was crucial to limit the volume (25–35 mappings) and demand a strict format.
Otherwise the model either:
- floods you with shallow matches, or
- becomes overcautious and gives you 5–7 pairs.
The outcome: 68 unit pairs that I can attach to real screens in the app.
3. Claude Code — Glue Between Data and Product
Separately, I used Claude Code as a working coding tool:
- parsing JSON from Perplexity and Sonnet
- mapping it onto the bot’s internal structures
- scaffolding an API layer behind the “Compare with EN/ES” button
This is already a small AI product stack, not “one magic model that does everything”.
How It Shows Up in the Bot’s UX
On the UX side I currently have three basic scenarios for showing hints:
- When a learner is reading theory → a “Compare with EN/ES” button
- When a learner answers incorrectly → if there is a relevant mapping, the bot adds:
- In all other cases → no hints are forced, the user keeps control
Perplexity is helpful here not only as a data generator but also as a UX advisor: when to surface comparisons and when to stay quiet so as not to overload the screen or the learner’s head.
What I Learned as a Product Person
A few conclusions that matter to me specifically from a product standpoint, not just as “someone who likes languages”:
- “The more cross‑lingual hints, the better” is the wrong target.
- The Perplexity + Claude combo beats a single all‑purpose tool.
- Code and data are only half the work.
- In this case, AI is not a “magic button” but an accelerator for research and prototyping.